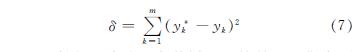典型的气候数据包括气压,温度,湿度,风向,风速,总云量,地表辐射强度,直接辐射强度,红外辐射强度等多个维度,各个维度之间彼此相互关联,相互作用,呈现出复杂的非线性关系,因此数据清洗前,需要对数据之间各个维度的关联关系进行挖掘与表征.BP神经网络作为当前理论最为成熟,应用最为广泛的一种神经网络模型,具备任意非线性函数描述能力,因此适合于对气候数据进行建模与分析.但是建筑气候数据具有高维、大数据量的特点,若直接利用BP神经网络进行建模时会出现模型复杂度高、网络训练时间长、运算量大等问题,因此本文将K-MEANS聚类算法与BP神经网络结果,首先利用K-MEANS对数据进行分析,将高相似度的数据聚集到同一模糊气候子类中,并使不同子类之间的差异尽量大,然后利用利用BP神经网络模型对每一模糊气候子类建模,降低模型复杂度.
图1给出了所提数据清洗算法的流程图,可以看出整个算法包含训练和测试两个阶段,其中训练阶段的具体实现可以总结为:
Step1:提取建筑气候数据典型指标(如气压,温度,湿度等)构成特征数据矩阵;
Step2:利用PCA对其进行分析得到大特征值个数K;
Step3:将Step2得到的K作为K-MEANS算法的聚类个数,然后利用K-MEANS算法对特征数据进行自适应聚类,根据相似性将数据集划分为K个子类;
Step4:根据表1所示步骤,对每个了类分别构建GSA-BP神经网络模型,得到K个网络用于对测试样本进行分析.
在测试阶段,对于给定的待清洗测试数据,利用所提方法对其进行清洗的具体实现步骤可以总结为:
Step1:子类划分,计算待清洗数据到训练阶段获得的每个子类之间的欧式距离,并将其划分至距离最小的子类中;
Step2:利用对应子类已训练好的GSA-BP网络模型对数据进行分析预测;
Step3:根据预测结果,按以下准则完成数据清洗:
(1)异常数据检测和修正:当测试点与左右相邻点的均值差异超过30%,且与网络输出点的差异超过30%时,判定该样本为异常数据,利用网络输出值和左右相邻点的均值对其进行修正;
(2)缺失数据填充:利用网络输出值对缺失数据进行填充.
图1 算法流程
Fig.1 Flowchart of the proposed method