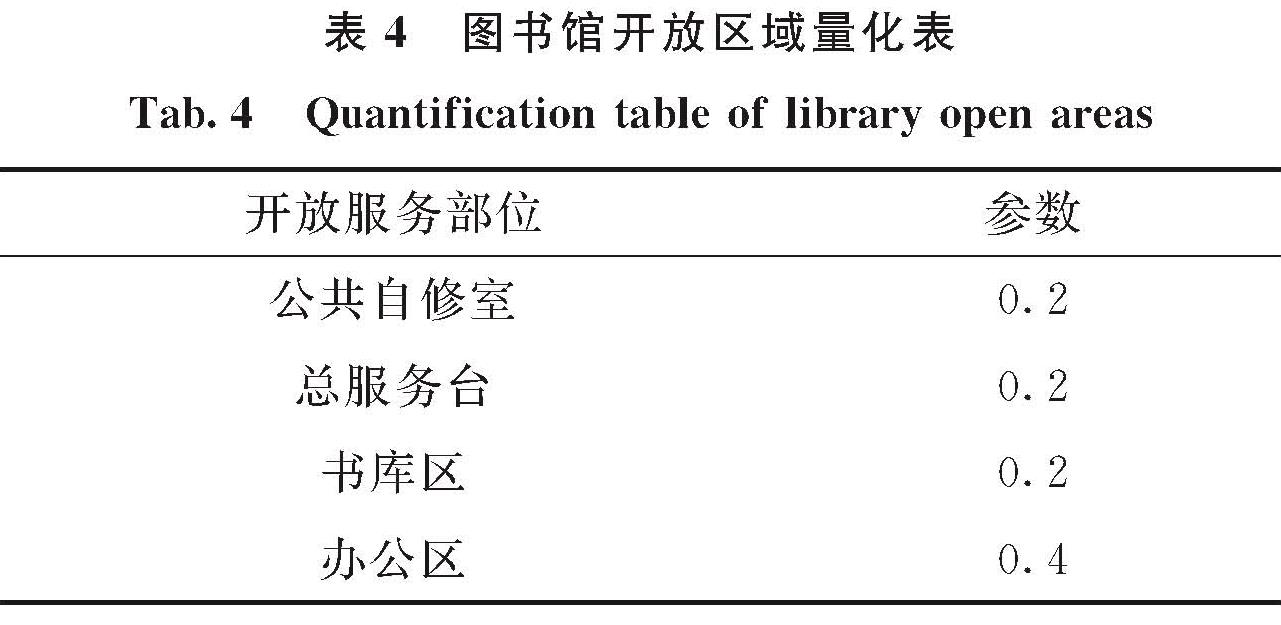
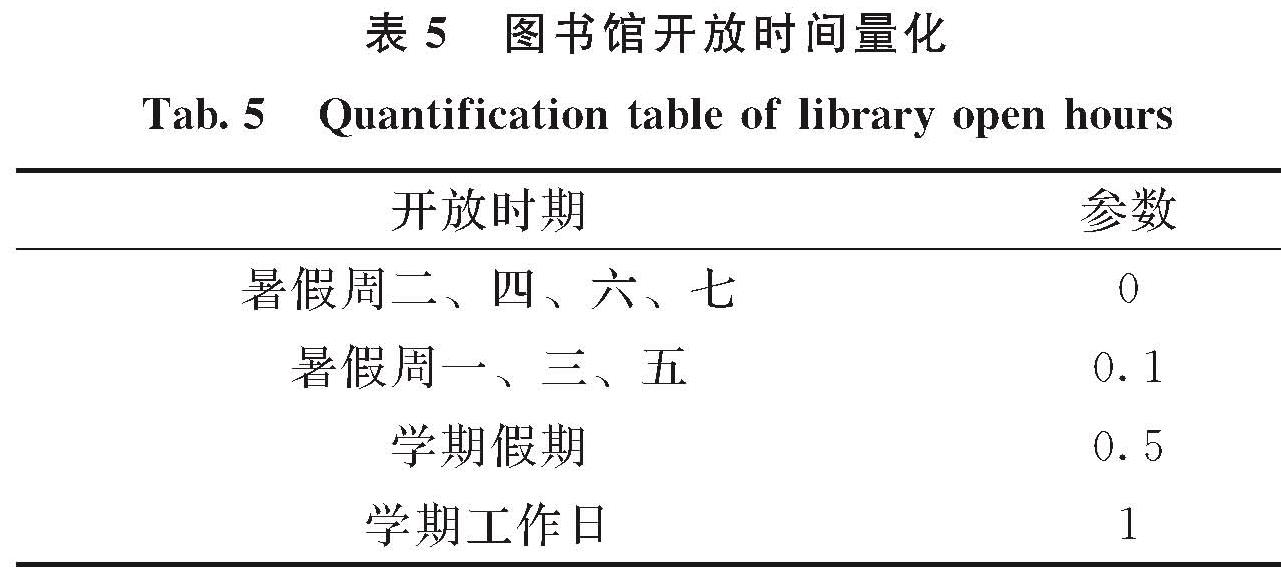
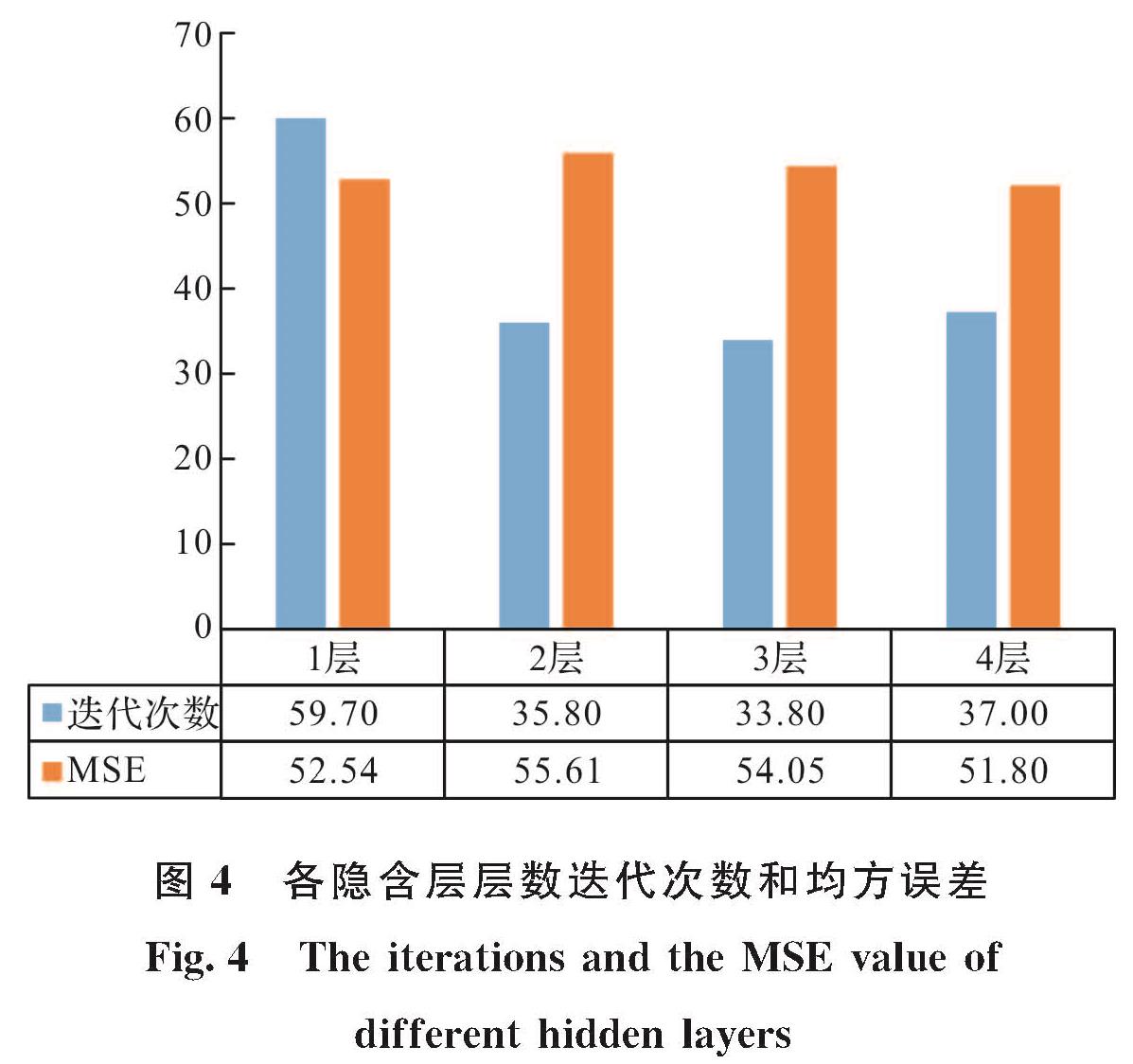
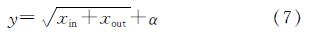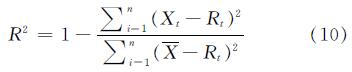2.1 数据来源
实例建筑来源于西北某高校图书馆,其室内人员数据根据门禁系统记录计算得到,其能耗数据来自高校内部的能耗监管平台,所使用的当地日均气温数据来自中国气象数据网.
图书馆的暑期时间表由2020年7月13日起实行至当年8月13日止,如表1所示.
表1 暑假图书馆开放时间表
Tab.1 Library opening schedule during summer vacation
表1 暑假图书馆开放时间表
Tab.1 Library opening schedule during summer vacation
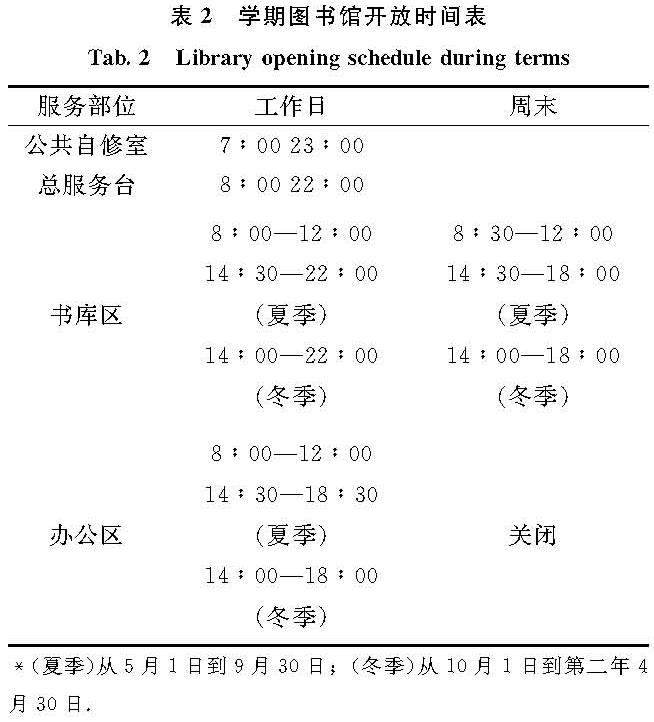
图书馆的学期开放时间表由2020年8月14日起开始实行,如表2所示.需要说明的是,在2020年10月1日至10月4日期间,由于节假日的缘故,除公共自习室于8:00—22:00开放外,其他区域关闭.
表2 学期图书馆开放时间表
Tab.2 Library opening schedule during terms
表2 学期图书馆开放时间表
Tab.2 Library opening schedule during terms
考虑可用性数据和研究价值,选取2020年7月14日至2020年11月30日的共6 700多条(包含能耗、气温和人数)数据进行研究.需要说明的是,能耗数据在2020年9月4日至7日出现记录缺失,但由于缺失的数据量很小,该缺失对整体研究结果造成的影响非常有限,因此,将其忽略.
2.2 数据分析
本研究对象为图书馆能耗,为确定其相似日特征向量及预测模型的输入参数,需要筛选出对该建筑物能耗影响较为重要的因素.因此,使用数据分析法对室内人员人数、日均气温与能耗数据进行了研究.
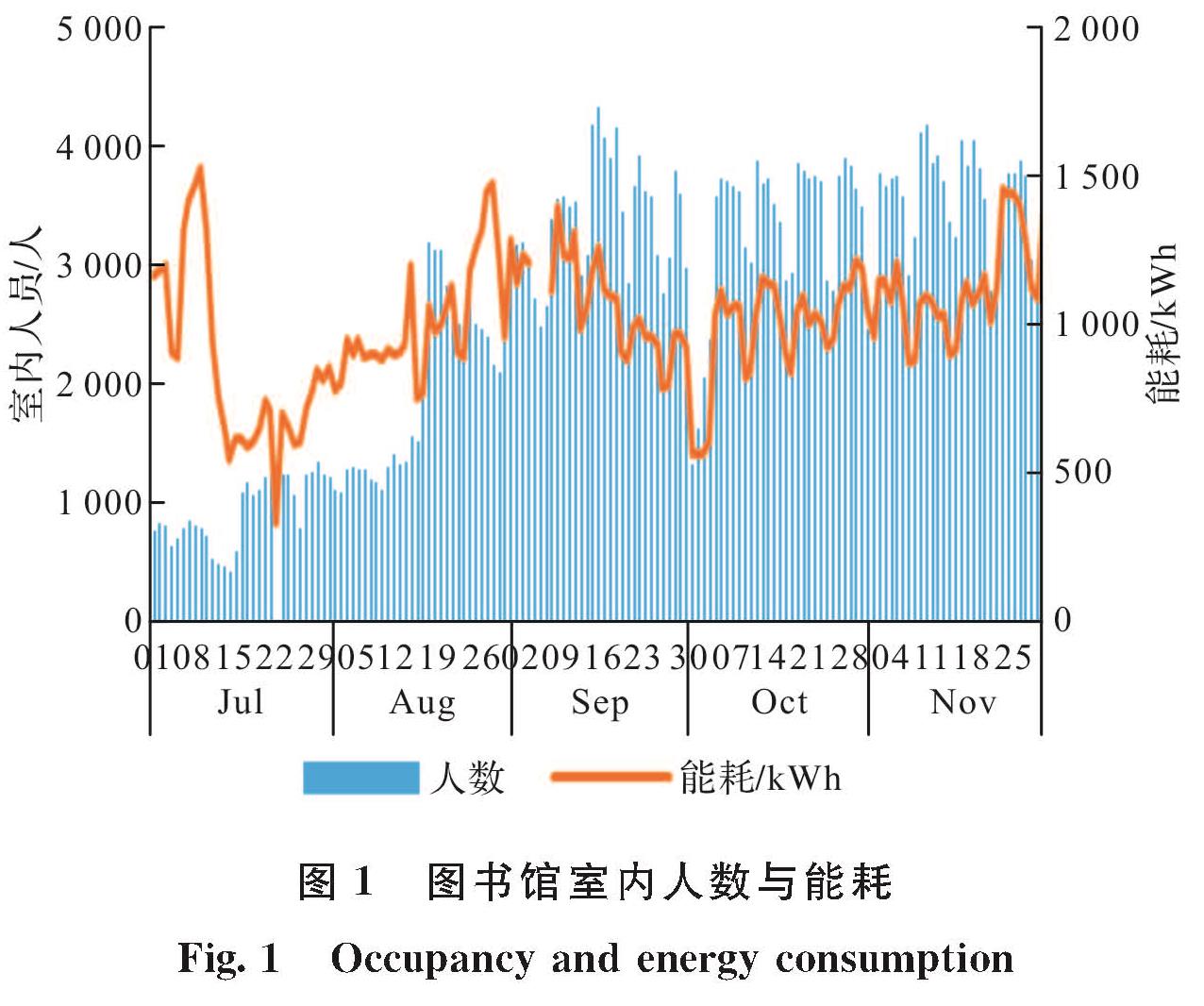
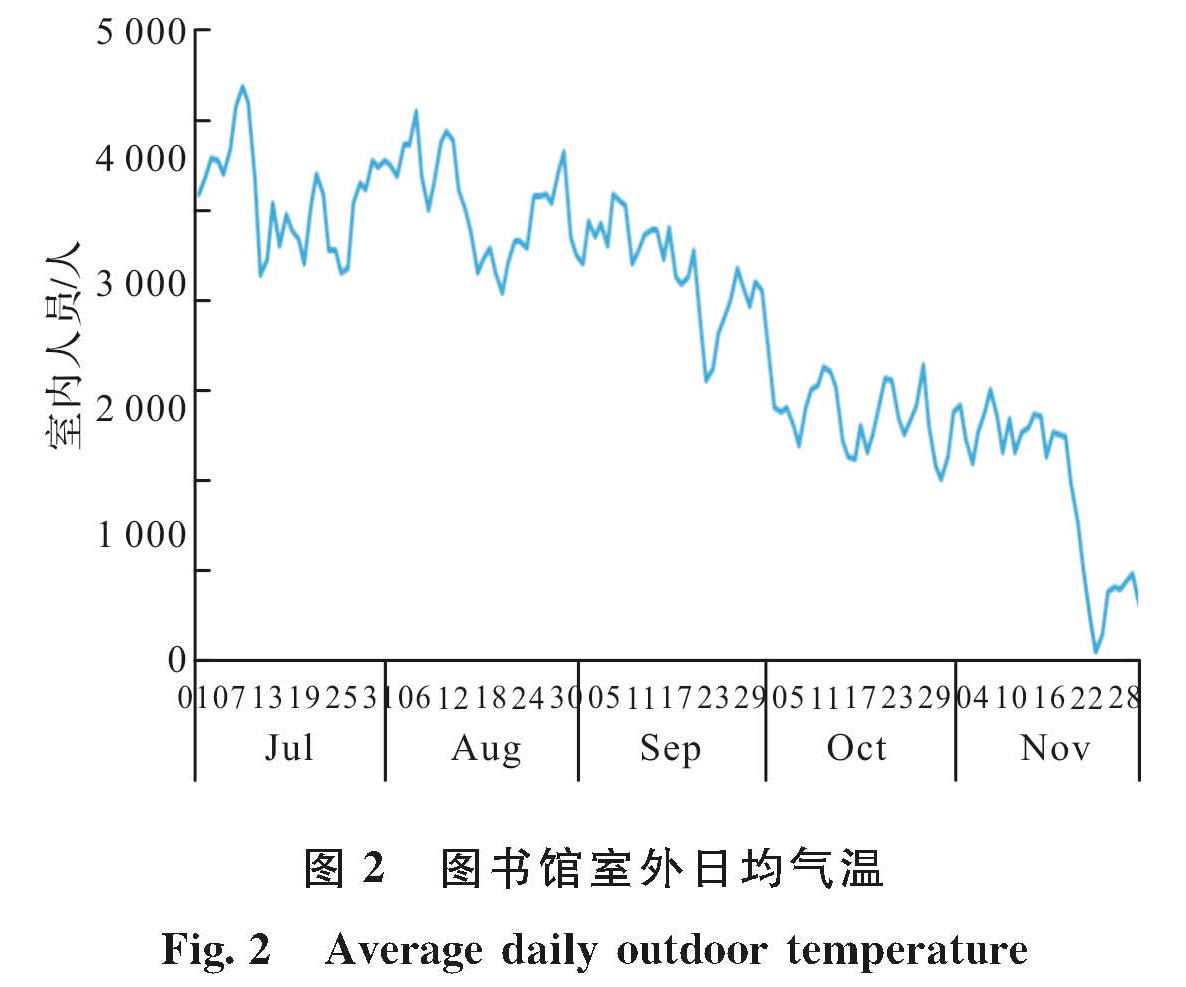
如图1所示,能耗存在三个高峰,包括两个夏季高峰和一个冬季高峰.如图2所示,夏季高峰期间,日平均气温高,而冬季高峰期间,日均气温断崖式下跌.为维持室内温度适宜,空调系统耗能较大.由此可知,气温对图书馆建筑能耗产生的影响不可忽视.
图1 图书馆室内人数与能耗
Fig.1 Occupancy and energy consumption
图2 图书馆室外日均气温
Fig.2 Average daily outdoor temperature
能耗于7月12日后出现快速大幅下跌.此时图书馆由于暑假原因调整开放策略,只图书馆总服务台及自修室开放,其他服务区域等基本全部关闭.由此产生的大量照明系统及其他系统相关设备的关闭导致此时能耗下跌严重.而在8月14日进入学期开放状态后,图书馆建筑能耗逐渐回升.因此,图书馆开放策略的调整会影响图书馆能耗的变化.
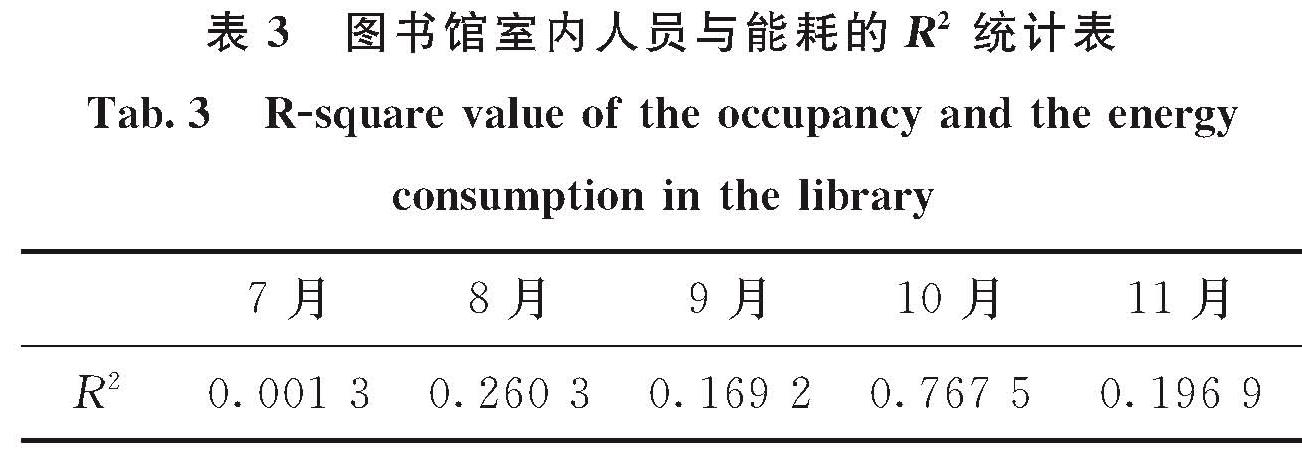
拟合度((R-squared,R2)可用来表示关系的线性程度,通常情况下,该值越接近1,则表示线性关系越明显.表3利用R2对室内人员和能耗之间的关系进行了统计.从表3中可以发现,能耗的波动与室内人数的变化存在一定关系,但各月份R2存在较大波动,即室内人员对能耗的影响程度在不同时期存在差别.结合前文对气温和开放策略对图书馆能耗的影响分析可推测,在某些月时期,气温或开放策略对能耗的影响超过了室内人员的影响,而其他时期反之.根据实际数据,R2在7月下半月为0.678 5,在9月下半月为0.912,在11月上半月为0.441 2,均显著高于当月总体R2,且发生时间与气温或开放策略发生显著变化的时间大致吻合.由此可知,室内人数变化对该建筑能耗具有一定影响,但由于存在其他影响因素的相互作用,其影响程度会有所不同.
表3 图书馆室内人员与能耗的R2统计表
Tab.3 R-square value of the occupancy and the energy consumption in the library
表3 图书馆室内人员与能耗的R2统计表
Tab.3 R-square value of the occupancy and the energy consumption in the library
综上所述,室内人员人数、气温和图书馆开放策略都是对能耗影响较大的因素.