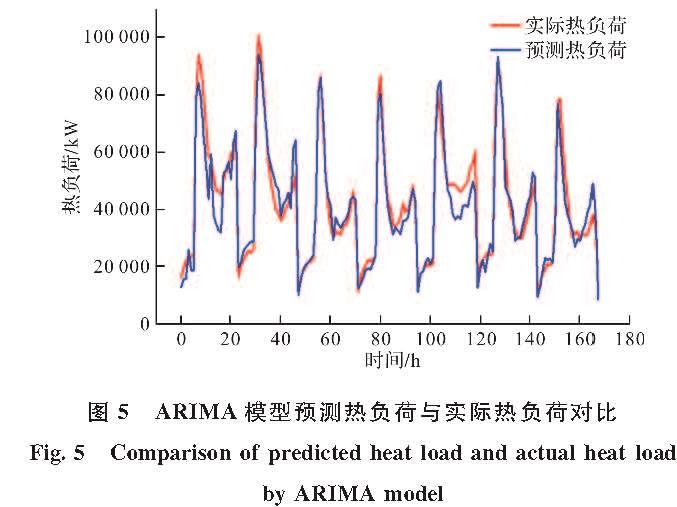
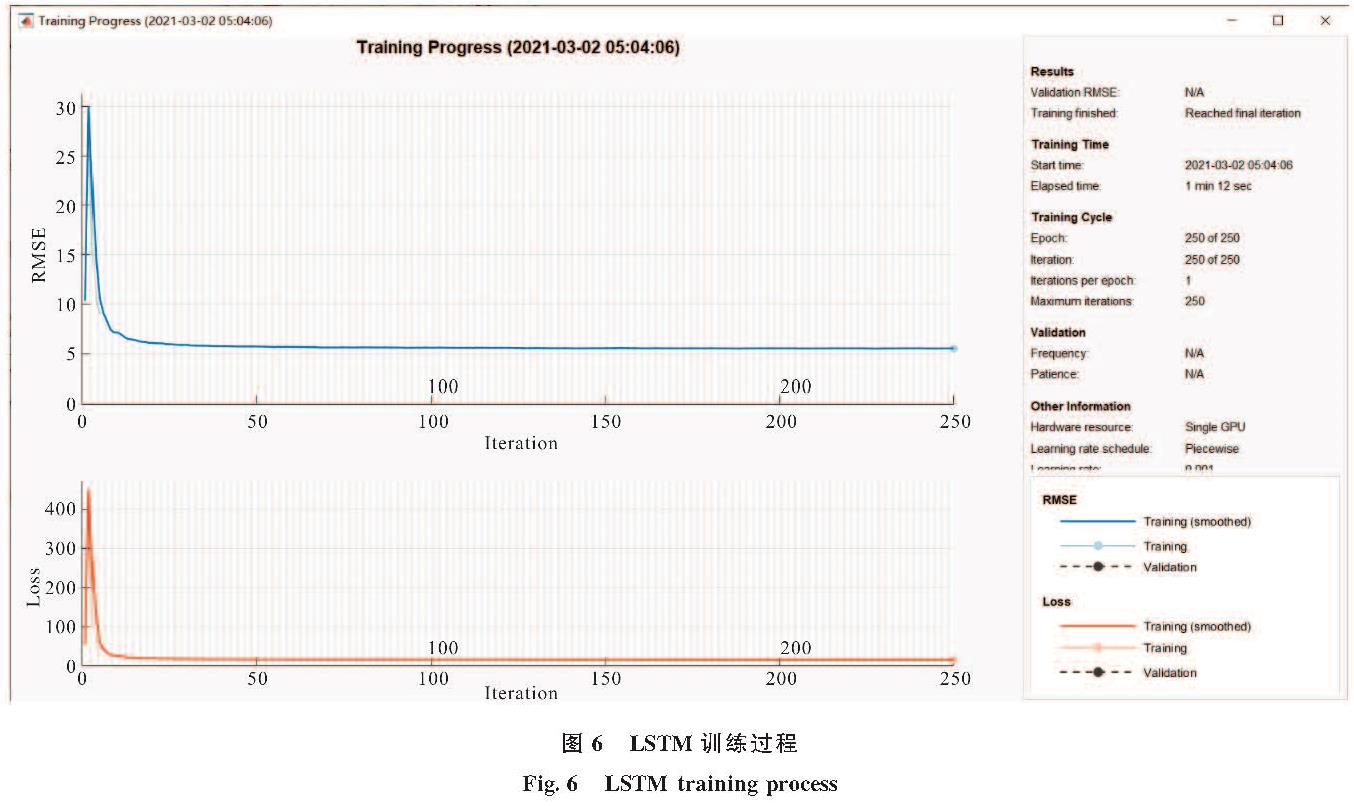
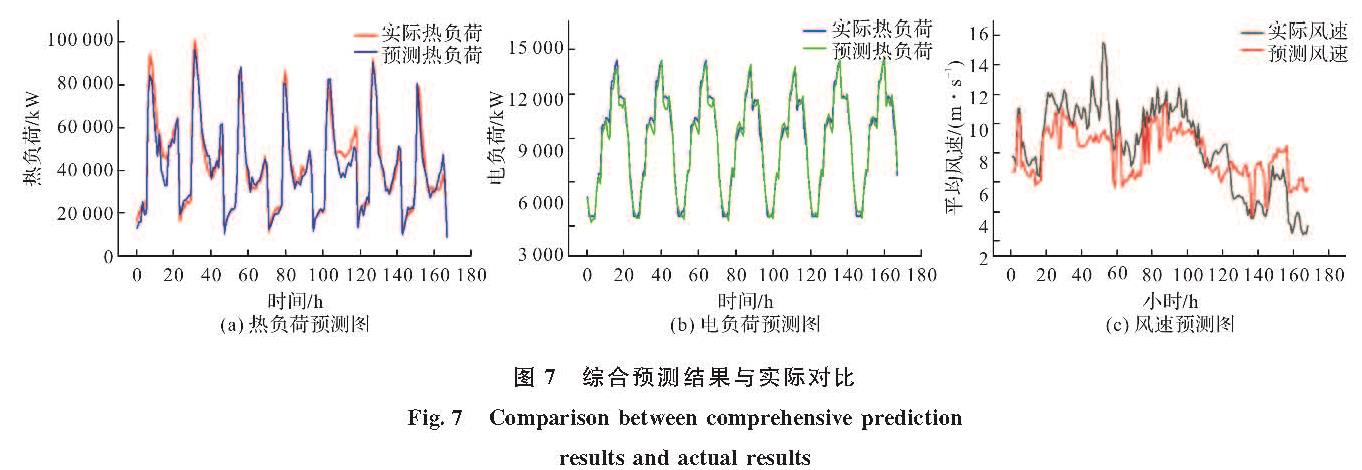
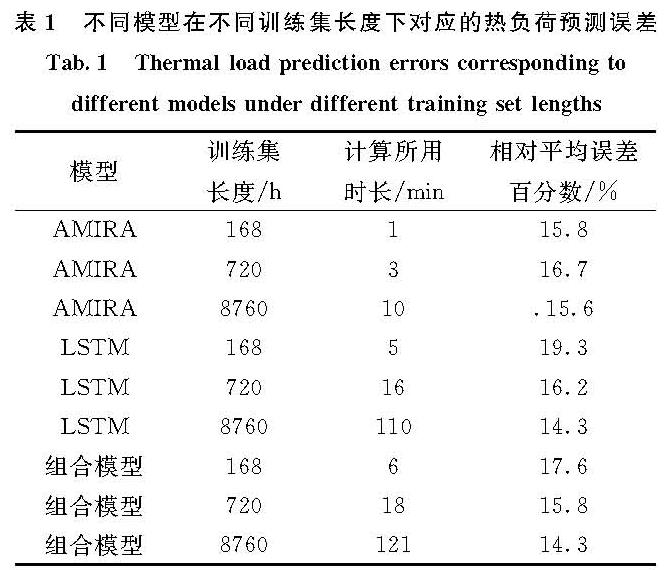
ARIMA模型全称为移动差分自回归移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA),是用于预测平稳时间序列的最受欢迎的线性回归模型之一[16],且有预测所需数据量较小的特点.LSTM网络全称为长短期记忆网络(Long-Short Term Memory,LSTM),是拥有强大处理非线性数据的模型 [17],它成功的解决了原始循环神经网络梯度消失的问题,能够很好地处理时间序列数据[18].受到这两种模型自身特点的启发,提出了ARIMA-LSTM综合预测模型.
1.1 ARIMA预测模型
ARIMA模型表示为ARIMA(p,d,q),其中参数p,d和q表示预测模型的结构,该模型可拆分为自回归AR(p),移动平均值MA(q)和差分度d.
AR(AutoRegressive,自回归模型)模型确定当前时间序列观测值,是先前时间序列观测值加上一些噪声项的线性组合.参数p为自回归模型的阶数.
MA(Moving Average,移动平均值)模型中,当前时间序列值是过去误差的函数.移动平均预测模型使用预测误差的误差值来改进当前的预测,参数q为移动平均的阶数.
I代表差分操作,它主要是对等周期间隔的数据进行线性求减.从而使数据变得平稳,ARIMA一般进行一次差分即可稳定,因此d一般取值为0、1、2.
ARIMA(p,d,q)的数学公式可以描述如下.
xi=α0+α1xi-1+α2xi-2+L+αpxi-p+
ε0+β1εi-1+β2εi-2+L+βqεi-q (1)
式中:αp,βq为时间序列的自相关系数.
模型的建立过程:构建ARIMA模型的一般过程涉及三个迭代步骤.
第一步为模型识别和选择模型类型.为了判断最佳拟合模型,固定时间序列必不可少,在该序列中,基本统计属性(例如均值,方差,协方差或自相关)随时间是恒定的.为了构建平稳时间序列,使用了适当的微分度(d).然后,检查自相关函数(ACF)和部分自相关函数(PACF)以选择模型类型;
第二步为参数估计.选择q和p的阶数,在ARIMA模型中,许多学者已经基于Akaikes信息标准(AIC)、最小描述长度(MDL)、贝叶斯信息标准(BIC)或模糊系统等开发了许多方法[19].在本文的研究中使用AIC指标来估计参数;
最后一步为对残值(εt)分析的诊断检查.通过一些诊断统计数据和残差图检查偏差,包括残差白噪声检验,及判断E(εt)是否为零,为零则代表模型通过检验,不同时刻的变量之间不相关,反正则相反,需要修正模型.
1.2 LSTM预测模型
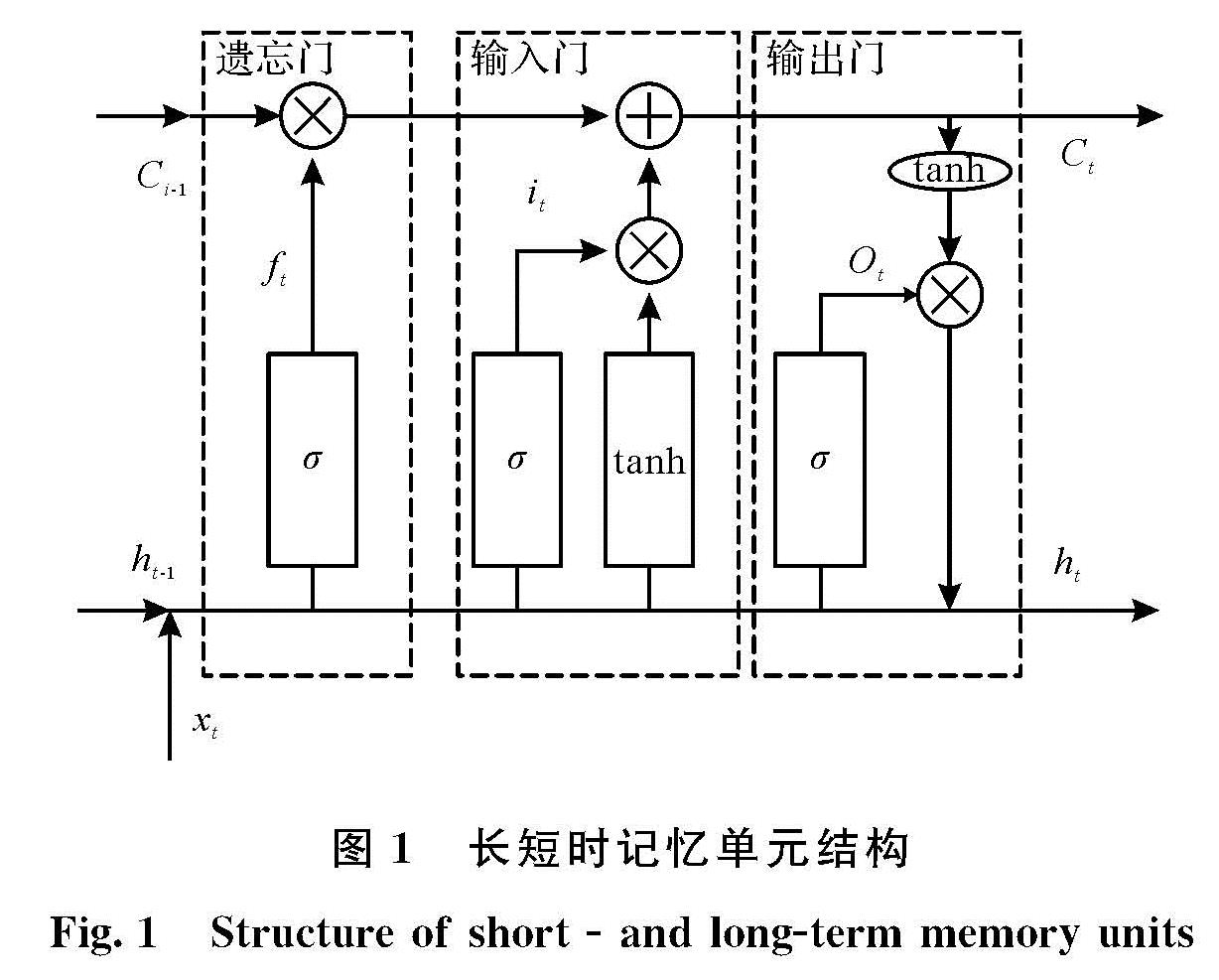
LSTM网络是递归神经网络(Recurrent Neural Network,RNN)的扩展.由于LSTM模型在处理大尺寸参数方面具有多功能性,并且在每一层中都使用了非线性激活函数,因此,LSTM模型可以捕获数据中的非线性趋势并长时间记住以前的信息.LSTM已成功应用于许多时间序列问题.LSTM结构的优点是它包含三种类型的门,包括输入,忘记和输出.如图1所示,LSTM解决了RNN消失的梯度问题,并允许长期存储信息.
图1 长短时记忆单元结构
Fig.1 Structure of short and long-term memory units
LSTM单元(图1)的主要信息流可以用数学方式描述.符号+和×表示模型中的加法和乘法,箭头表示信息的流向.存储器门的第一层确定将不必要的信息删除到单元状态,可以表示如下.
ft=σ(Wf×xt+Uf×ht-1+bf) (2)
式中:ft表示在时间忘记门,σ表示sigmoid函数,Wf和Uf表示权重xt表示输入值,ht-1表示在时间t-1的输出值,并且bf表示偏差项.
第二个输入门根据当前输入向量决定应在单元状态下存储哪些信息.同时由tanh层生成新的状态值Ct.具体表达式如下.
it=σ(Wi×xt+Ui×ht-1+bi) (3)
C^-t=σ(Wc×xt+Uc×ht-1+bc) (4)
式中:it表示在时间t的输入阈值,Wi,Ui,Wc,和Uc是重量bc和bi是偏见.为了在时间t更新单元格的状态,表达式如下.
Ct=ft×Ct-1+it×C^-t (5)
第三输出门作为输出信息生成,可以表示如下.
Ot=σ(Wo×xt+Uo×ht-1+bo) (6)
式中:Ot表示在此时的输出值,Wo和Uo是权重,并且bo是偏差项.然后,该单元的输出值可以表示如下.
ht=Ot×tanh(Ct) (7)
式中:表示时间t单元的输出值,tanh表示激活函数,并且Ct表示在时间t的单元状态.数据通过三个门之后,将输出有效信息,并会忘记无效信息.
1.3 ARIMA-LSTM 预测模型
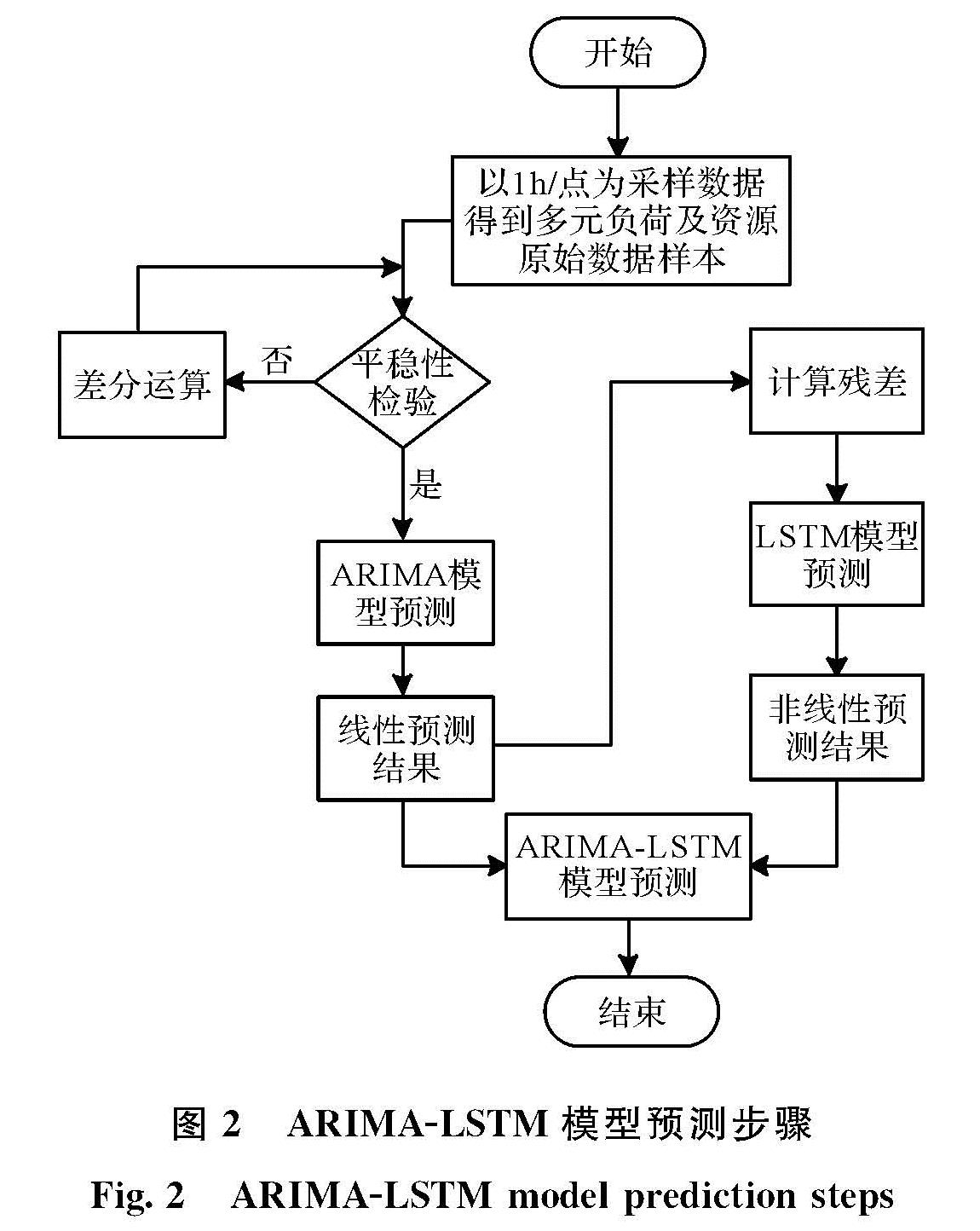
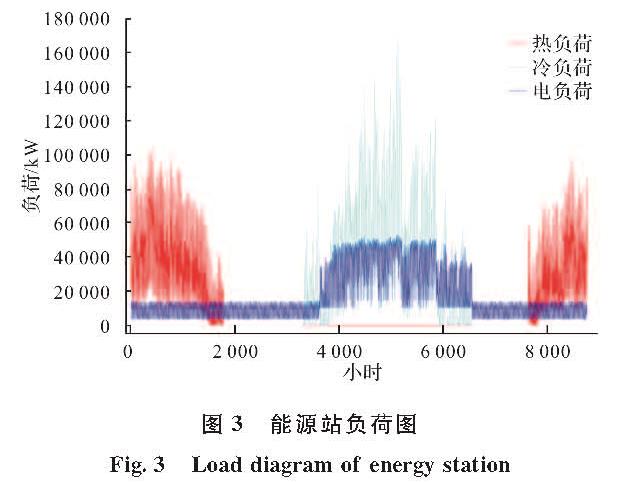
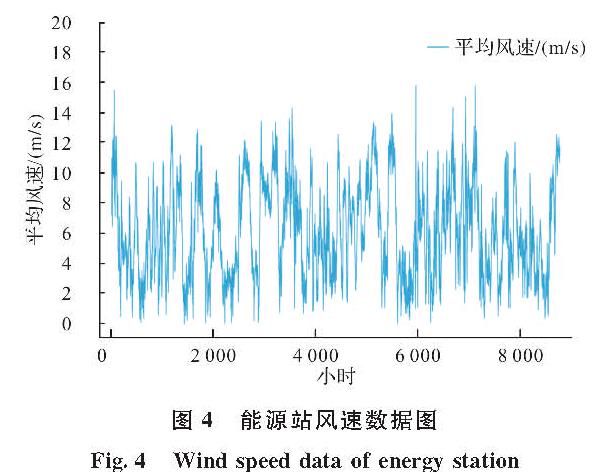
综合能源系统中的多元负荷数据及资源数据(风速和太阳日辐射量)为时间序列数据的形式,多元负荷数据均可假定由线性部分和非线性部分组成,ARIMA方法可以成功地建模时间序列数据中的线性关系,而LSTM可以成功地建模非线性分量.为了达到最佳的预测结果,本文构建了混合模型,如图2所示,它们结合了ARIMA和LSTM方法的优势.即ARIMA-LSTM预测模型,用公式可以表示为
Lp,t=Lap,t+Llp,t (8)
式中:Lp,t为综合预测序列; Lap,t为ARIMA模型预测序列; Llp,t为LSTM模型预测序列.
图2 ARIMA-LSTM模型预测步骤
Fig.2 ARIMA-LSTM model prediction steps
基于图2中提出的方法的工作流程.
综合模型建模流程可以分为以下几个步骤:
(1)通过数据采集等方法获取历史数据.
(2)平稳性检验,平稳的数据指其基本统计属性(例如均值,方差,协方差或自相关)随时间是恒定的.若数据不平稳,则需要进行差分运算.差分运算是将非平稳的时间序列进行平稳化的运算方法.如果1阶差分不能使序列达到平稳的话,本文还可以继续进行差分运算,直到将序列转换为平稳序列为止.差分公式如下.
1阶差分
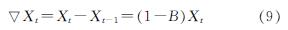
2阶差分
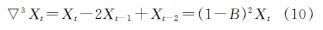
以此类推,可d阶差分为

式中: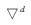 为d阶差分算子.
为d阶差分算子.
(3)模型定阶:
通过差分运算得到了ARIMA(p,d,q)模型中的其中一个参数d,接下来就要确定对参数p和q进行定阶,这里用到的定阶方法就是AIC准则,方法如下.
假设Xt为ARMA(p,q)模型,其中未知参数的个数为p+q+1个,其中包括自回归系数φ1,φ2,…,φp、移动平均系数θ1,θ2,…,θq和σ2ε,那么ARMA(p,q)的定阶准则为
选取适当的p和q,使得AIC值达到最小,AIC计算公式为[19]
AIC=nln(^overσ)2ε+2(p+q+1) (12)
式中:n为样本容量,(^overσ)2ε与p、q有关.
若当p=p',q=q'时,值最小,则认为模型的阶数为p'和q',即为ARMA(p',q')模型.
(4)ARIMA模型的线性预测.应用ARIMA统计模型提取生产时间序列的线性部分Lap,t,并计算拟合误差,这是下一步的输入项.设原始负荷数据集为H=[h1,h2,h3,…,hn],利用ARIMA模型得到H的历史数据拟合序列F和预测序列Lap,t.
F=[F1,F2,F3,…,Fn]
Lap,t=[Lap,1,Lap,2,Lap,3,…,Lap,n]
(5)将拟合序列F与相应负荷实际序列Hf相比较,得到拟合误差序列
ΔF=[ΔF1,ΔF2,ΔF3,…,ΔFn]
(6)LSTM建模的非线性预测.ARIMA模型的残差是LSTM机器学习模型的输入.因此,本文预测非线性数据计算公式为
Llp,t=f(ΔF1,ΔF2,ΔF3,…,ΔFn) (13)
式中:f(…)为LSTM的非线性建模.
(7)耦合和评估ARIMA-LSTM模型的最终结果.通过将ARIMA模型的预测结果与到LSTM网络的预测结果结合,可以获得拟合得出时间序列的最终结果.随后进行预测评价.
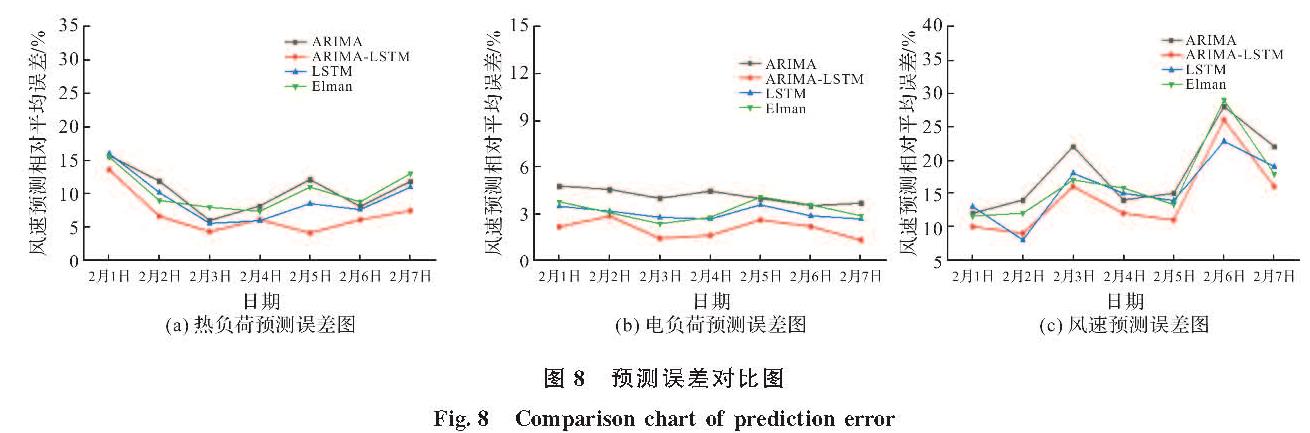
1.4 预测性能评价
为了评估不同实验场景下的预测性能,选择科学的评估指标进行时间序列预测.作为评估指标常用的包括:均方根误差(RMSE),平均绝对误差(MAE),平均绝对百分比误差(MAPE)和相似度(Sim),这些指标用于评估不同模型在预测结果中的性能,并且可以表示如下.
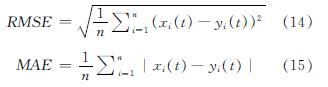
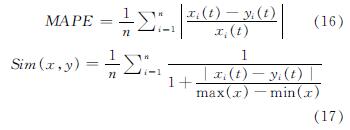
式中:xi(t)表示多元负荷数据值; yi(i)表示通过不同模型预测的产量值; n表示时间序列数.通常,RMSE,MAE和MAPE的值越低,预测任务的性能越好.此外,Sim值在[0,1]区间内,较高的Sim值表示较好的拟合结果.