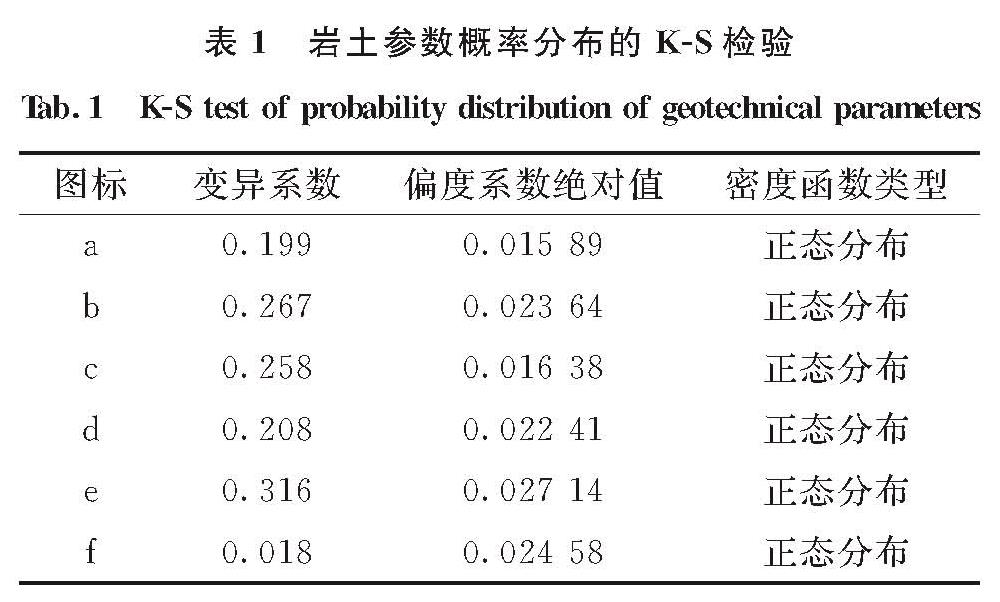
图标 变异系数 偏度系数绝对值 密度函数类型a 0.199 0.015 89 正态分布b 0.267 0.023 64 正态分布c 0.258 0.016 38 正态分布d 0.208 0.022 41 正态分布e 0.316 0.027 14 正态分布f 0.018 0.024 58 正态分布
1.1 Bayes-Bootstrap法扩大样本及超参数计算
由图1可知三种土的力学参数样本量最大的为粉土,n=90; 泥炭质土的最小n=66.与文献[9]相比样本量还较少,因此需对岩土参数进行扩充,使样本量n≥200.骆飞[12] 、孙慧玲[13-14] 、何成铭[15]等对Bayes- Bootstrap法下的数据的重构提出了不同的方法.综合对比各种方法下的数据重构,最后发现基于插值法改进的Bayes-Bootstrap法比一般的Bayes法或者Boot- strap法的数据重构不仅存在效率较高,而且也能逐步扩展到取样之外的样本信息的优势.故本文把勘察得到的小样本作为先验信息,基于插值法改进的Bayes- Bootstrap法对样本进行扩充.方法如下:
设x1,x2,x3,…,xn是从某层土的总体样本中随机抽取的有限样本,并将这些样本按照某一步距h随机分为k组(h,k都为整数),其中h=n/k.每组样本里有h个数据,B1=(x1,x2,…,xh),…,Bk=(xk,xk+1,…,xn ).其中k=n-h+1.则样本量矩阵为

此时仅对原样本分组,样本容量没有得到改变.改变样本量的方法是对每组数据进行从小到大排序:
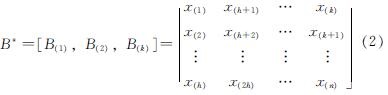
对x(i)的观测值的做邻域可得
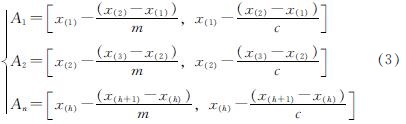 (3)
(3)
经笔者试算取不同的m值时采用式(3)扩展形成的样本与原始数据的相似度很高,不足以表征地层的总体信息,因此把式(3)加以改正,采用另外一种方式去对样本量进行扩展,如式(4).
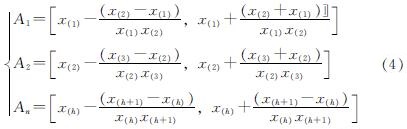
此时x(0)便可从式(5)中确定(取区间的左端点值):
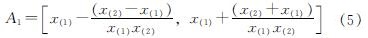
x(h+1)从式(6)中确定(取区间的右端点值):
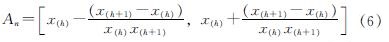
每次计算结束后样本增加2个,之后对第2组到第k组的样本量进行重复操作,完成之后样本总量扩充为n1+2k个,依次重复上述步骤,直至样本达到各个参数的样本量n≥200.之后做出各个参数样本频率直方图如图2.同理可做出K-S检验表,也能验证图2也是符合正态分布的.但限于篇幅问题,不再一一列举.
图2 插值改进Bayes-Bootstrap扩充后的样本分布图
Fig.2 The sample distribution after extended Bayes-Bootstrap
从图1和图2可知,岩土力学参数的先验与后验分布基本都符合正态分布,在得到先验信息与样本信息分布之后根据文献9所提供的方法计算后验超参数,以确定后验分布表达式,文献[2]也指出在样本分布为N(μ,σ2)的正态分布时,样本的后验分布为服从t(vn,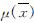 ,σ2n/kn)参数的一元t分布,vn,
,σ2n/kn)参数的一元t分布,vn, ,σ2n/kn为后验的超参数,具体计算方法参见文献[9].相关参数计算后归入表2.
,σ2n/kn为后验的超参数,具体计算方法参见文献[9].相关参数计算后归入表2.
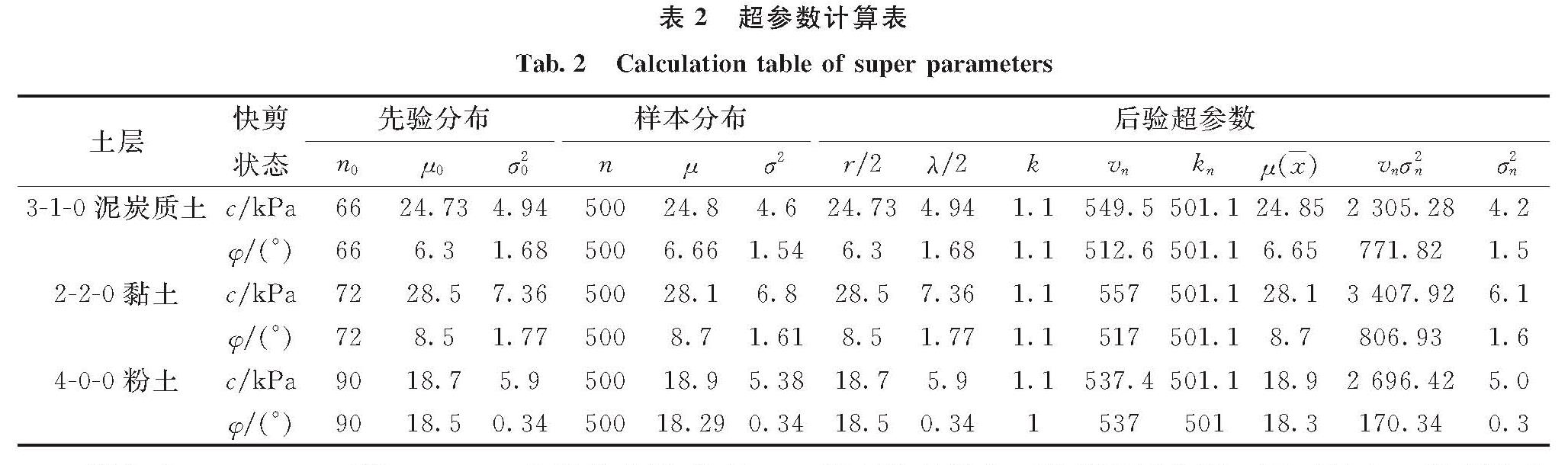
表2 超参数计算表
Tab.2 Calculation table of super parameters
表2中n0、μ0、σ0和n、μ、σ分别为先验分布图1中及改进Bayes –Bootstrap扩展后的分布图2中样本的样本量、均值和标准偏差.得到超参数后,通过MATLAB做出三种土六种参数的先验、样本、后验分布图,如图3.
从图3可以看出,三种土六个参数的先验分布与样本分布的形式基本一致.因为在数据重构过程中某个值的频率如果很大,该值在数据重构时所占比重会很大,故先验分布与样本分布均值很接近,一定程度上对原始先验样本的依赖性较高,故两者的相似性较高.另外随着样本增加参数均值也是逐渐收敛的,也说明岩土参数不需要达到200以上,仅需要一个合适的样本量,此时既能得到准确的参数取值,也可节约成本.另外比较三种土c的后验分布都较先验分布、样本分布集中,取值更加方便; 而三种土φ的后验分布则表现出与样本和先验分布之间区别不是很大,从表1可知三种土φ的先验与样本分布中标准偏差σ2都较小(最大为1.77),故数据间的离散性不是很强,导致Bayes大样本法的后验分布与样本和先验分布相比的效果不是很明显,尤其4-0-0层粉土φ的(σ2=0.34)后验分布的拟合效果远不及样本和先验分布,但是由于样本的增加,最大后验分布密度可信区间是在减小的,这与分布的形式无关.图3也在一定程度上说明了样本的增加,确实可更准确、更方便地确定岩土参数的取值.随着样本的增加,各地层参数取值是逐渐收敛的,但是样本应该取为多少?也就是说没必要把样本量勘察很大,需要一个合理的样本量,它既能节约成本,又能带来准确的地层信息.
图3 力学参数样本、先验、后验概率分布图
Fig.3 Sample, prior and posterior probability distribution of mechanical parameters
1.2 岩土参数Bayes法最大后验密度可信区间
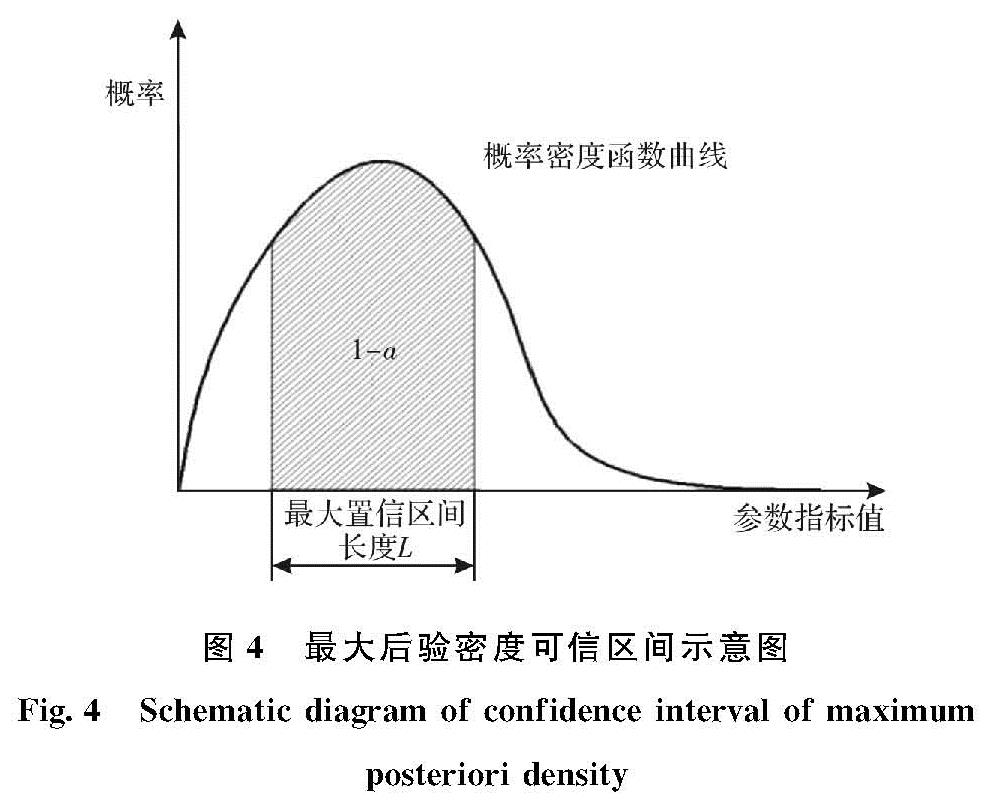
通常情况下一个区间的选择是否合理,区间的精度即区间长度是可以通过可信度1-α来反应的.理论上区间可信度1-α越大,区间越短效果越好.通常寻找最优可信区间的方法是给定一个α,控制可信度(本文中α=0.05,即可信度为95%),寻找长度最短的区间.通常可获得的可信度为1-α的区间不止一个,但必定会有一个是最短的[2].等尾可信区间[16]在实际中应用较为广泛,且计算方便,但是不是最好的,即区间长度还不是最短.若后验分布是单峰对称,则等尾可信区间是最好的.要使可信区间最短,并且把后验密度的点都包含进去,而在区间外的点的后验密度值都不会超过区间内的点的后验密度值,这样的区间就称为最大后验密度可信区间,如图4所示.
图4 最大后验密度可信区间示意图
Fig.4 Schematic diagram of confidence interval of maximum posteriori density
样本足够大时,参数μ后验分布可用一个与先验分布无关的分布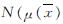 ,I-1n(μ))来代替[9],其中
,I-1n(μ))来代替[9],其中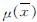 为大样本情况下后验分布均值,I-1n(μ)为其观测Fisher信息量的倒数,在后验分布为一元t分布时:
为大样本情况下后验分布均值,I-1n(μ)为其观测Fisher信息量的倒数,在后验分布为一元t分布时:
I-1n(μ)≈(σ2n)/(kn) (7)
其中,kn=n+k.
此时参数μ的最大后验密度可信区间为
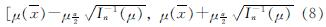
式中:μα/2为标准正态分布N(0,1)情况下上侧分位数,α=0.05时取1.96.岩土力学参数在工程中采用标准值[1],标准值可以采用下式确定.
μk=γsμ (9)
式中:μk为土体参数标准值; γs为统计修正系数,即
γs=1±((1.704)/(n1/2)+(4.678)/(n2))σ/μ (10)
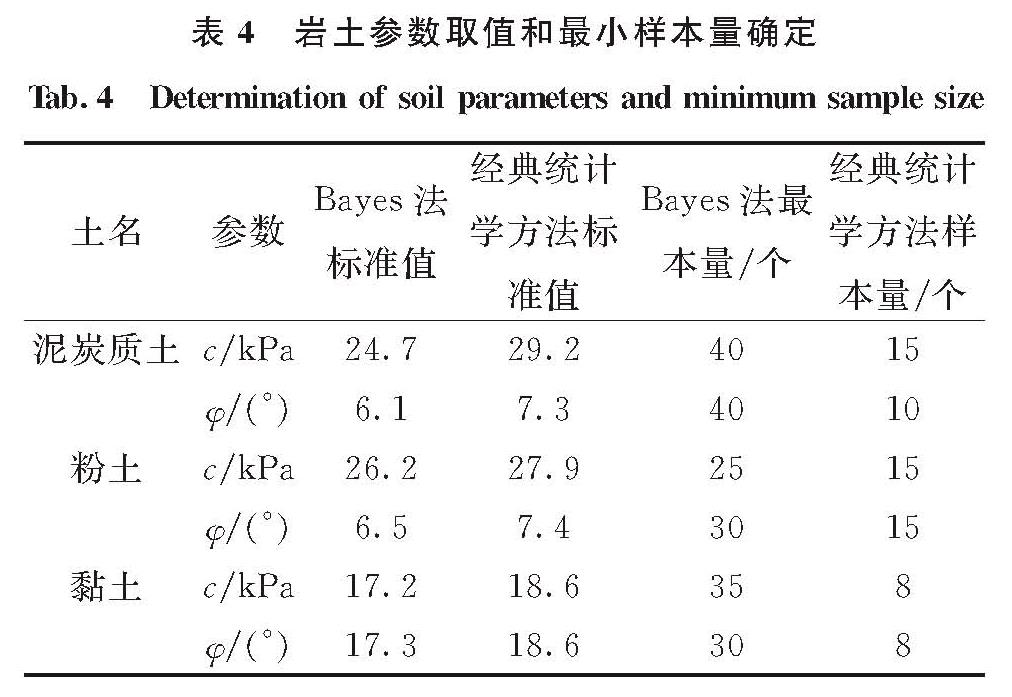
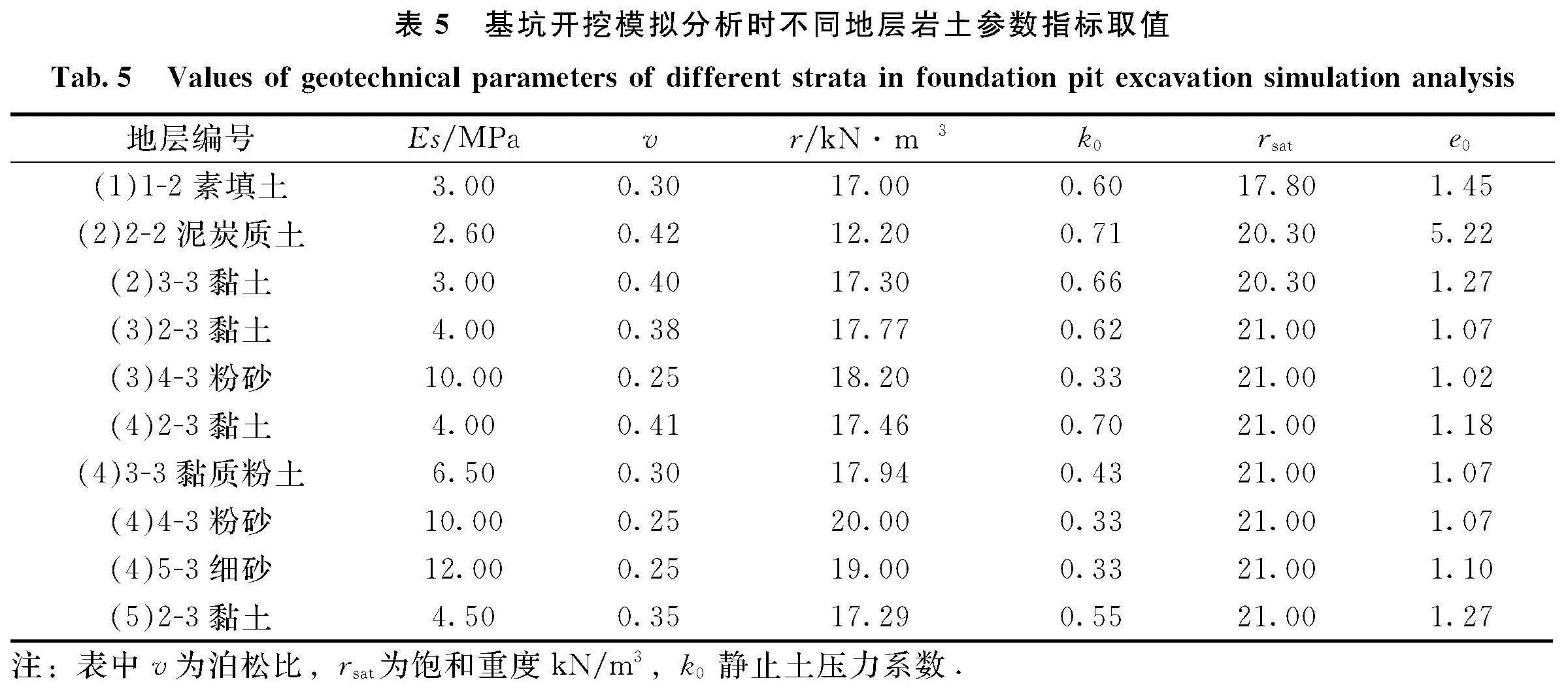
考虑到不利组合,对于抗剪强度指标γs取负号[1],式中n、μ、σ分别为Bayes –Bootstrap扩展后的样本分布图3中样本量、均值和标准偏差.据此就可得到三种土c、φ的最大后验密度可信区间、标准值、经典统计学区间等,如表3.
表3 力学参数的后验密度可信区间
Tab.3 Posterior density confidence interval of mechanical parameters
从表3中可直观地看出三种土的力学参数的标准取值都在最大后验密度可信区间与典统计学区间内,并且与最大后验密度可信区间的差距更小.经典统计学区间长度总体比最大后验密度可信区间长,过于保守,因其上限值都比最大后验密度区间大,下限比最大后验密度区间小.最大后验密度区间较短,在参数的取值上比经典统计学的取值更加方便,在此证实了Bayes大样本方法的实用性.值得指出的是:4-0-0层粉土φ样本分布的标准偏差虽然很小,但在同一置信水平下经典统计学区间还是比Bayes大样本最大后验密度可信区间长,这是因随样本量增多时,从获得的样本中可观测到费希尔信息量I(μ)也会逐渐增加,对样本总体分布情况的掌握度会更全面,导致I-1n(μ)会减小,区间长度变得较短.这也在一定程度上说明了最大后验密度可信区间与分布的形态无关,主要取决于所勘测到的样本信息值.
 与样本均值
与样本均值 和样本量n之间的关系反算岩土参数达到可靠值时所需样本量的最小量.并通过一个基坑开挖工程,结合开挖过程中的深层水平位移的实际监测数据和改变参数情况下的有限元模拟深层水平位移数据进行对比,验证Bayes-Bootstrap法确定参数的可行性.
和样本量n之间的关系反算岩土参数达到可靠值时所需样本量的最小量.并通过一个基坑开挖工程,结合开挖过程中的深层水平位移的实际监测数据和改变参数情况下的有限元模拟深层水平位移数据进行对比,验证Bayes-Bootstrap法确定参数的可行性.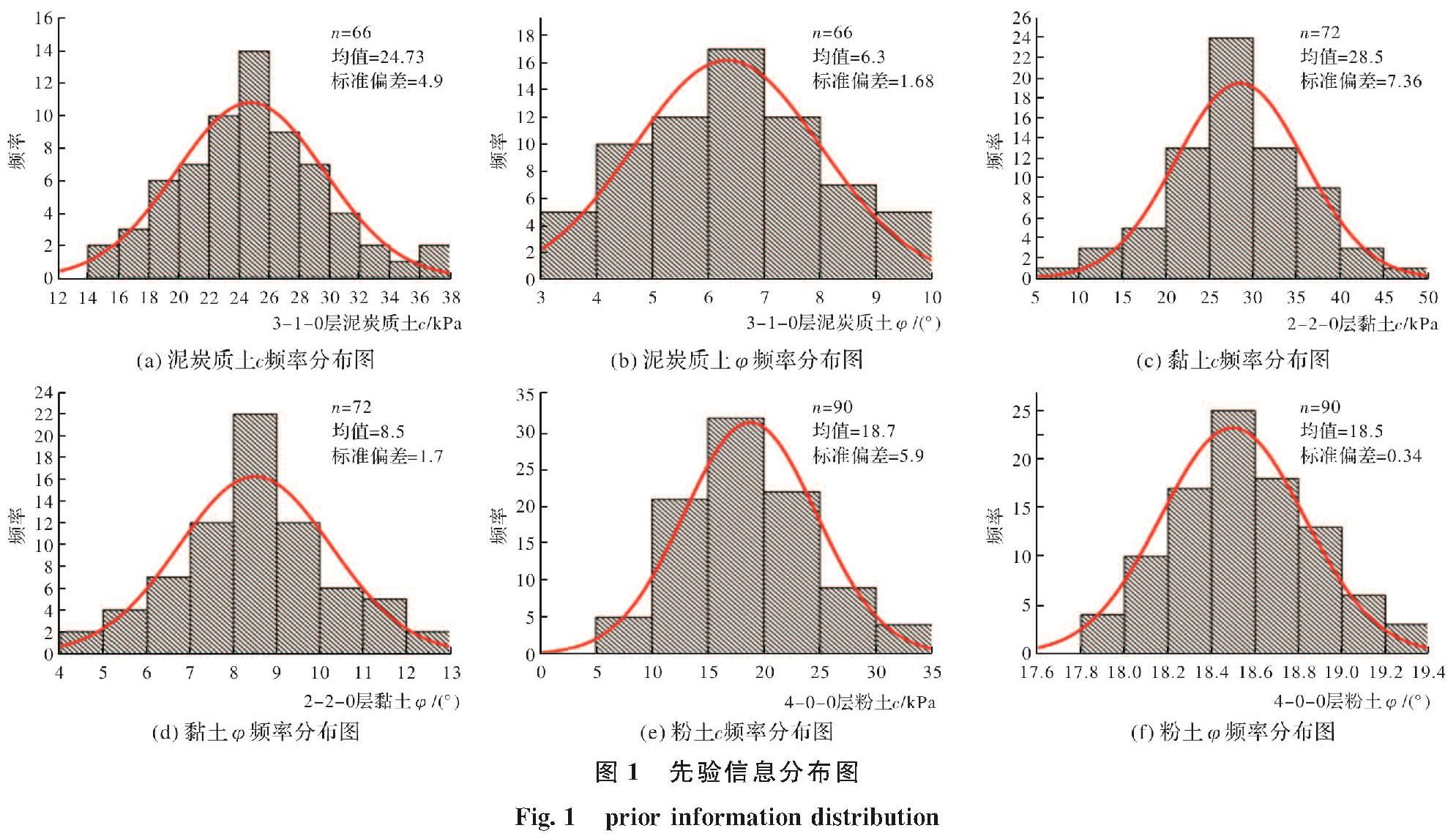



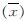 的值,据此可寻找最小样本量,让力学参数均值达收敛值附近.
的值,据此可寻找最小样本量,让力学参数均值达收敛值附近. 为
为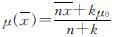 (12)
(12)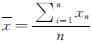 ,k=λ/(2σ),k、λ为后验超参数; μ0为先验信息均值.
,k=λ/(2σ),k、λ为后验超参数; μ0为先验信息均值.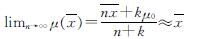 (13)
(13)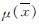 为后验均值; n为样本量; k、λ为先验超参数,因为本文已经从大样本的情况下论证了岩土力学参数在本文的样本量时是收敛的,故而k、λ可以保守地取
为后验均值; n为样本量; k、λ为先验超参数,因为本文已经从大样本的情况下论证了岩土力学参数在本文的样本量时是收敛的,故而k、λ可以保守地取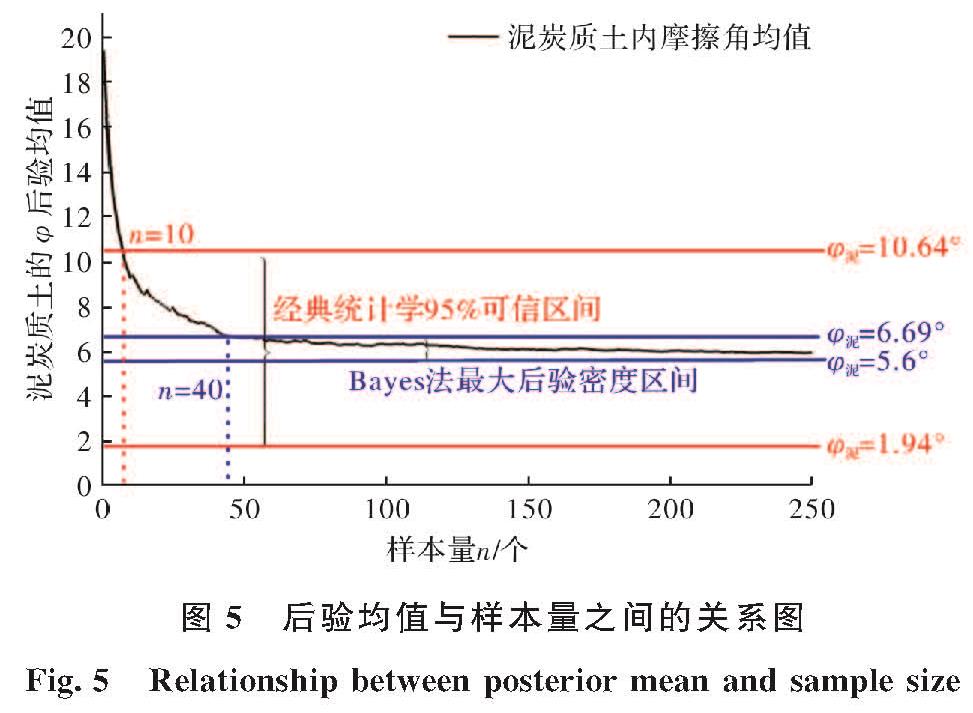
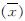 开始时随样本量的增加也在不断波动,当样本量到达某个值时,后验均值
开始时随样本量的增加也在不断波动,当样本量到达某个值时,后验均值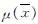 逐渐稳定下来,且不再随样本的变化而变化.本文采用的样本量是远远大于所需最小样本量,故计算结果能很好地体现地层的总体信息,为小样本方法提供检验,有很好的工程意义.
逐渐稳定下来,且不再随样本的变化而变化.本文采用的样本量是远远大于所需最小样本量,故计算结果能很好地体现地层的总体信息,为小样本方法提供检验,有很好的工程意义.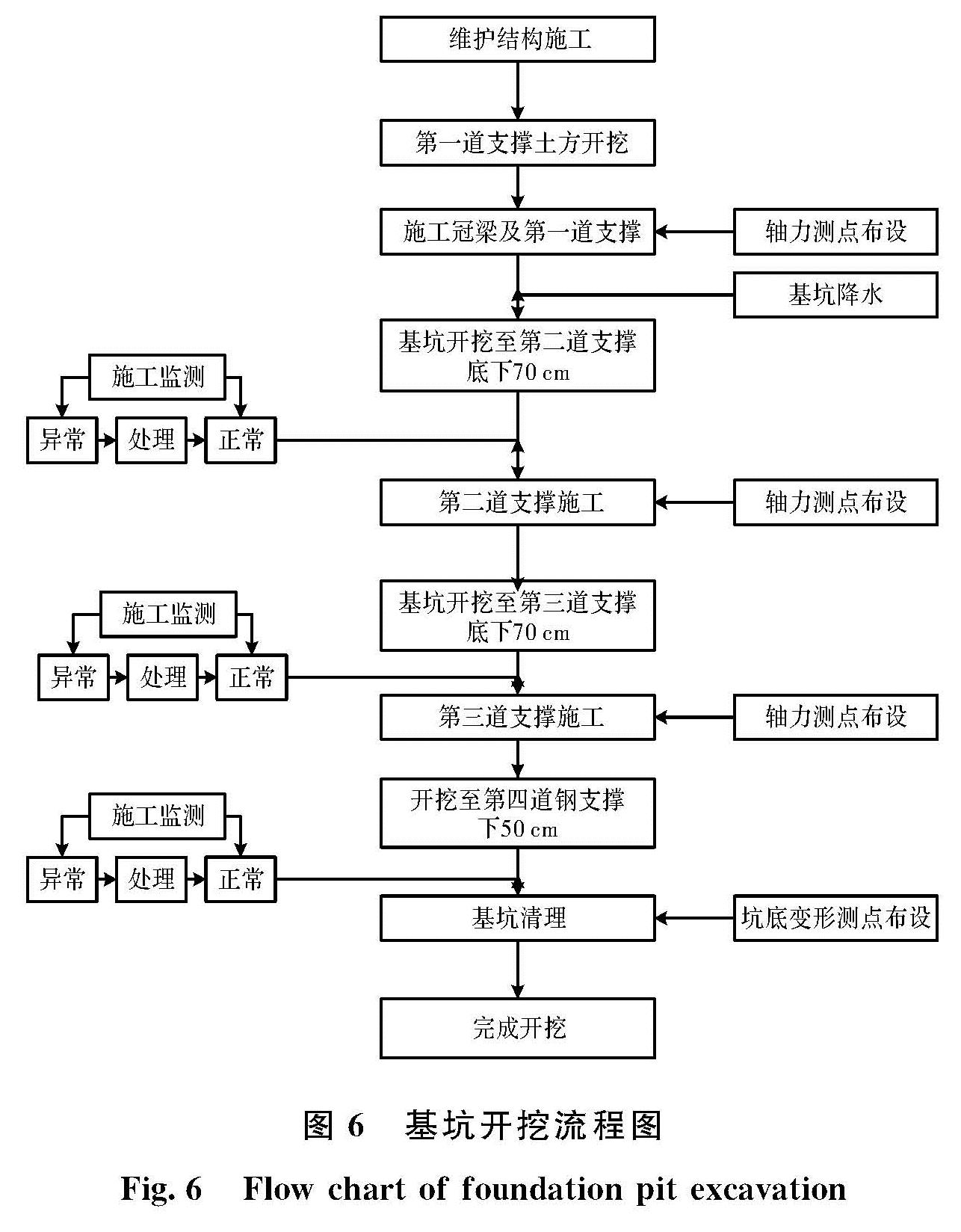



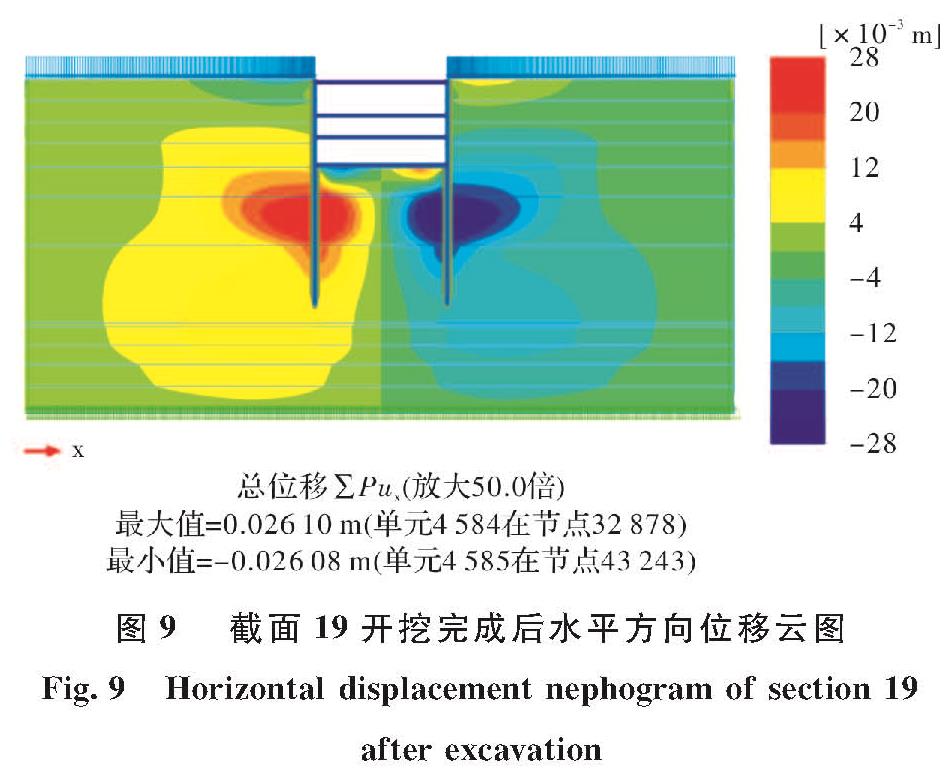

 靠近,先验分布的影响逐渐减小,误差数据逐渐被洗去;
靠近,先验分布的影响逐渐减小,误差数据逐渐被洗去; 